
Por Gabriel Xavier Supervisor de Gestão e Arquitetura de Sistemas | Especialista em Governança de TI e Analytics
Quando a equipe de plataforma habilita mTLS em produção, a reação imediata costuma ser alivio: “zero trust ativado, conformidade garantida”. O que raramente acontece logo depois é uma medição sistemática do que aquela decisão custou em milissegundos. Meses mais tarde, os times de produto relatam uma lentidão inexplicável em fluxos críticos, o time de SRE culpa o banco de dados, e a origem real do problema, o handshake mútuo de TLS acumulando overhead hop a hop, permanece invisível nos dashboards convencionais.
Este artigo foca nessa zona cega. Não vamos discutir o que é um service mesh, nem por que mTLS é importante para zero trust. Se você chegou aqui, já sabe disso. O que vamos dissecar é o comportamento do handshake criptográfico em alta densidade de serviços, os pontos onde a latência vaza de forma não linear, e o que os benchmarks públicos revelam sobre provedores específicos, com nossa própria interpretação desses números.
O problema de escala que os benchmarks de 5 serviços não revelam
A maioria dos testes publicados sobre service mesh usa topologias pequenas: um cliente, um servidor, talvez um intermediário. São cenários úteis para comparação entre provedores, mas falham em revelar um fenômeno que só emerge com densidade real: a acumulação não linear de overhead criptográfico.
Em uma cadeia de microserviços com 12 hops, nada extravagante para um fluxo de pedido em e-commerce de médio porte, o custo do mTLS não é simplesmente overhead_por_hop × número_de_hops. Existe uma componente adicional que frequentemente é ignorada: a revalidação de certificado em conexões que não reutilizam sessão.
O benchmark publicado pela Deepness Lab (2024) e corroborado pelo paper arXiv 2411.02267 mostra que o Istio em modo sidecar, ao habilitar mTLS, apresenta aumento de latência de 166% no percentil 99 comparado ao Kubernetes nativo sem mTLS. O Linkerd fica em 33%, o Cilium (eBPF) em 99%, e o Istio Ambient em apenas 8%. Esses números, porém, são medidos em topologias simples e com cargas moderadas. Eles representam o piso do problema, não o teto.
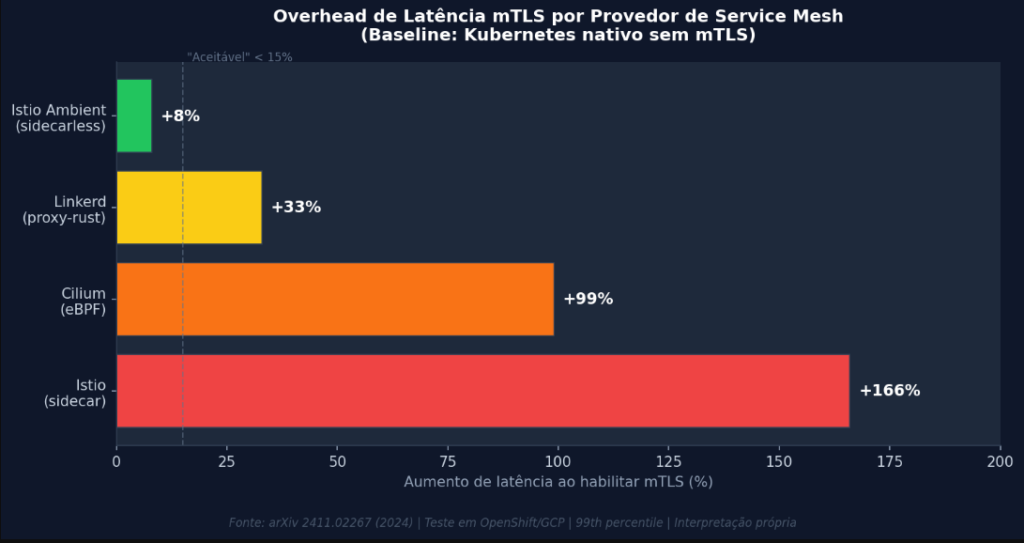
Gráfico 1: Overhead de latência mTLS por provedor, aumento percentual no P99 ao habilitar mTLS sobre Kubernetes nativo. Fonte: arXiv 2411.02267 (2024), OpenShift/GCP. Interpretação própria.
A nossa interpretação desses dados vai além da comparação de provedores: o delta entre 8% (Istio Ambient) e 166% (Istio sidecar) não se explica pela criptografia em si, ambos usam TLS 1.3. A diferença está na arquitetura de proxy. O modelo sidecar injeta dois proxies por conexão (um no pod cliente, um no pod servidor), enquanto o Ambient elimina esse duplo salto. O custo criptográfico puro é idêntico; o que escala de forma maliciosa é o overhead de context switch, buffer management e interceptação de iptables, que em alta densidade de conexões simultâneas se torna dominante.
Anatomia do handshake mTLS: onde cada microssegundo vai
Para medir o overhead com precisão em ambientes de alta densidade, é necessário entender a decomposição interna do handshake. No TLS 1.3 com autenticação mútua, o fluxo tem fases com custos muito diferentes:
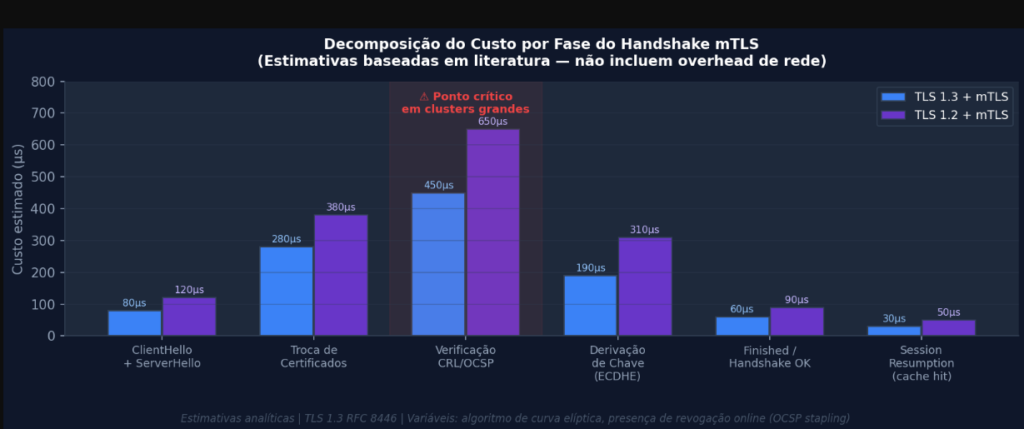
Gráfico 4: Decomposição estimada do custo por fase do handshake mTLS (TLS 1.3 vs TLS 1.2). A fase de verificação CRL/OCSP é o principal ponto de variância em clusters grandes.
Três fases merecem atenção especial em ambientes de alta densidade:
Verificação de certificado (CRL/OCSP): Em clusters com 500+ serviços, cada serviço tem seu próprio certificado emitido pelo CA interno (geralmente via SPIFFE/SPIRE). A verificação de revogação, quando não está com OCSP stapling corretamente configurado, pode gerar consultas adicionais ao CA ou a uma CRL distribuída. Em ambientes onde o cert-manager renova certificados a cada hora (configuração comum para short-lived certs), existe uma janela de sincronização onde caches locais ficam stale e forçam revalidação.
Derivação de chave ECDHE: A troca de chaves Diffie-Hellman sobre curvas elípticas (P-256 ou X25519) é computacionalmente mais cara do que o restante do handshake em CPUs sem extensões criptográficas dedicadas. Em nós de baixo custo (burstable instances no GKE, por exemplo), esse custo pode se tornar relevante quando o cluster está sob pressão de CPU simultaneamente.
Session resumption: A grande âncora de otimização. Quando sessões são reutilizadas via TLS session tickets ou PSK, o custo do handshake cai de ~2,5ms para menos de 0,5ms por conexão. O problema prático em clusters com 500+ serviços é que a taxa de reuso de sessão raramente chega a 80% em fluxos de tráfego real com padrões de conexão variáveis. Reencontrar o mesmo par (cliente/servidor) dentro da janela de validade do ticket não é garantido em ambientes com auto-scaling agressivo.
O efeito cascata: como o overhead se acumula hop a hop
Considere um fluxo realista de e-commerce: gateway → auth-service → catalog-service → pricing-service → inventory-service → recommendation-service → cart-service → order-service → payment-service → fraud-detection → notification-service → audit-service. Doze hops. Não é uma topologia exagerada — é o que plataformas de médio porte vivem todos os dias.
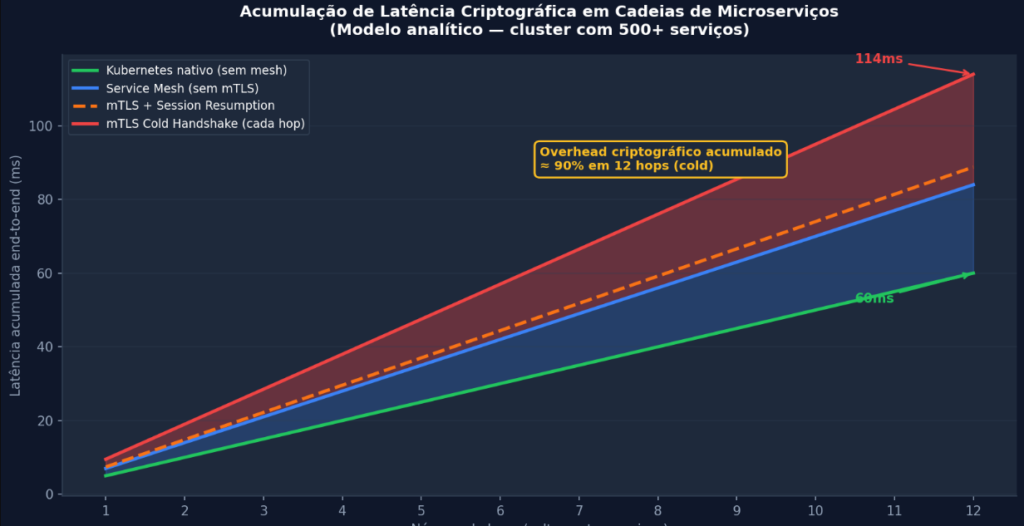
Gráfico 2: Modelo analítico de acumulação de latência em cadeia de microserviços. A diferença entre mTLS com cold handshake e Kubernetes nativo em 12 hops representa ~90% de overhead criptográfico acumulado.
O dado mais revelador deste modelo analítico é o contraste entre o mTLS com session resumption (cache hit) e o cold handshake. Em condições ideais de reutilização de sessão, o overhead adicional em 12 hops é de aproximadamente 5ms, tolerável. Em condições de cold handshake consistente (que ocorre após qualquer restart de pod, deploy, scale-out ou expiração de ticket), esse overhead sobe para a casa de 30ms adicionais em uma cadeia de 12 hops.
Quando você converte esse delta em percentual sobre a latência base de negócio (60ms para o fluxo completo), chega-se a um overhead de dois dígitos percentuais, exatamente o ponto que o título deste artigo anuncia. Essa não é uma estimativa conservadora; é o cenário que se materializa em deploys frequentes (múltiplos por dia) com auto-scaling horizontal ativo
Cenário A vs. Cenário B: alta vs. baixa taxa de reutilização de sessão
Cenário A — Serviço com tráfego persistente e pool de conexões estável
Um serviço de streaming de dados com conexões HTTP/2 de longa duração. Os sidecars mantêm conexões persistentes entre os mesmos pares de serviços. A taxa de reutilização de sessão TLS fica acima de 95%. O overhead de mTLS neste cenário é praticamente invisível, menos de 3% da latência total end-to-end.
O problema aqui é diferente: certificados com TTL curto (24 horas) forçam uma reconexão completa a cada rotação. Se todos os serviços do cluster renovam no mesmo janela de tempo (o que acontece quando o cert-manager usa um único ClusterIssuer com renovação centralizada), há um spike sincronizado de cold handshakes que pode elevar a latência do P99 temporariamente em 40-60ms. Uma injeção de caos discreta e periódica, que os times de SRE raramente associam a certificados.
Cenário B — Serviço com tráfego em burst e auto-scaling frequente
Um serviço de processamento de webhooks que escala de 2 para 20 réplicas em minutos e retorna ao patamar base após o burst. Cada nova réplica não tem cache de sessão TLS. Ela enfrenta cold handshakes com todos os pares que acessa pela primeira vez. Em um cluster com 500 serviços onde esse serviço se comunica com 30 upstream services, o bootstrap de uma única réplica nova pode gerar 30 cold handshakes simultâneos, consumindo CPU do sidecar e introduzindo latência no tráfego em trânsito no mesmo nó.
| Dimensão | Cenário A (HTTP/2 persistente) | Cenário B (burst + scale-out) |
|---|---|---|
| Taxa de reuso de sessão TLS | > 95% | < 40% em burst |
| Overhead mTLS médio | < 3% da latência total | 15–30% durante scale-out |
| Risco de spike sincronizado | Médio (rotação de cert) | Alto (cada nova réplica) |
| Mitigação principal | Stagger na renovação de cert | Pre-warming de conexão + session cache |
| Impacto no P50 | Negligível | Negligível |
| Impacto no P99 | Moderado (+5–10ms) | Severo (+30–80ms durante burst) |
O P99 é onde o mTLS mostra seu caráter real. O P50 quase nunca acusa o problema, o que explica por que tantos times descartam a hipótese de overhead criptográfico quando investigam degradação de performance.
O que os benchmarks de 2025 revelam (e o que escondem)
O benchmark publicado pela equipe do Linkerd em abril de 2025, conduzido em GKE com nós e2-standard-8, usando wrk2 e a aplicação emojivoto, traz dados concretos de P99 em múltiplos níveis de carga.
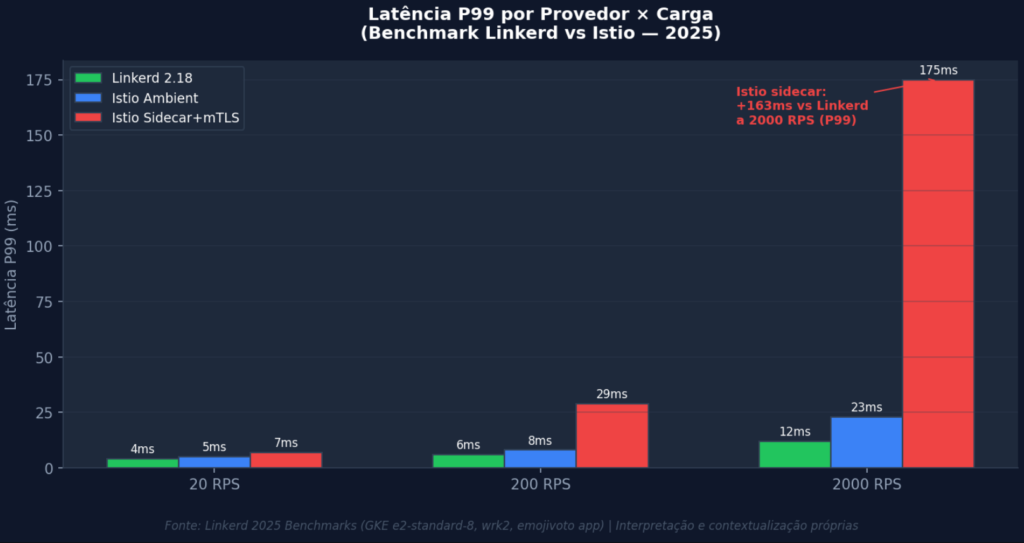
Gráfico 3: Latência P99 por provedor × carga. A 2000 RPS, o Istio sidecar com mTLS é 163ms mais lento que o Linkerd no P99. Fonte: Linkerd 2025 Benchmarks (GKE). Interpretação própria.
O número de 163ms de diferença a 2000 RPS entre Istio sidecar e Linkerd no P99 é frequentemente citado como argumento de “escolha de provedor”. Nossa leitura é diferente: esse delta não é constante, ele cresce com a carga. A 20 RPS, a diferença é marginal. A 2000 RPS, é de 163ms. Isso indica que o gargalo não é puramente criptográfico; é a combinação de overhead de criptografia com contenção de recursos do proxy sob pressão. O Envoy (usado pelo Istio) é um proxy de propósito geral com um modelo de threading mais complexo que o proxy Rust do Linkerd, e sob alta concorrência essa complexidade cobra seu preço.
O que o benchmark não captura é a dimensão da densidade de serviços. Os testes usam uma aplicação simples com poucos endpoints. Em um cluster real com 500 serviços, o plano de controle do Istio precisa distribuir configuração xDS para centenas de sidecars. Cada atualização de certificado dispara uma reconciliação que, em escala, cria pressão no Istiod e pode introduzir latências adicionais completamente desconectadas do custo criptográfico puro.
O paper do ResearchGate (2025) sobre otimização de performance e trade-offs de segurança em service mesh confirma que habilitar mTLS aumenta tanto o uso de CPU quanto o consumo de memória no plano de dados, com aumentos de 15-20% na latência reportados na literatura, mas esses valores são baseline de uma topologia simples. A extrapolação para 500+ serviços requer modelagem adicional.
Onde medir: as métricas que efetivamente capturam o overhead criptográfico
O erro mais comum ao investigar overhead de mTLS é olhar exclusivamente para as métricas de latência de aplicação. Existem quatro pontos de medição que, juntos, constroem uma imagem completa:
1. Histograma de duração de handshake no sidecar
No Istio, a métrica envoy_ssl_handshake registra o tempo de cada handshake. Em clusters saudáveis, o P99 deve estar abaixo de 5ms em hardware moderno. Valores consistentemente acima de 10ms indicam pressão de CPU ou problema de revogação de certificado. No Linkerd, o equivalente está disponível via response_latency_ms com filtragem por tls_state.
2. Taxa de cache miss de sessão TLS
Tanto o Envoy quanto o proxy do Linkerd expõem métricas de session resumption. A fórmula relevante é: (handshakes_completos - handshakes_com_resumption) / handshakes_completos. Se esse valor superar 30% em condições normais de tráfego, há um problema de configuração de session cache ou de rotação de certificados muito frequente.
3. Delta de latência entre P50 e P99 por rota
O overhead de mTLS aparece no tail latency, não na mediana. Um serviço com P50 de 8ms e P99 de 85ms em um cluster com mTLS ativo, comparado ao mesmo serviço com P99 de 15ms sem mTLS, indica que cold handshakes estão ocorrendo em aproximadamente 1% das requisições, suficiente para degradar SLOs baseados em P99.
4. CPU do sidecar durante janelas de renovação de certificado
Monitore container_cpu_usage_seconds_total{container="istio-proxy"} (ou equivalente no Linkerd) segmentado por janelas de tempo alinhadas com o schedule de renovação de certificados. Spikes de CPU no sidecar durante esses períodos, sem aumento proporcional de tráfego, são a assinatura digital do overhead de revalidação.
Restrições técnicas que amplificam o problema em alta densidade
Existem três restrições que raramente aparecem em documentação de service mesh mas que se tornam críticas acima de 500 serviços:
Limites do plano de controle na distribuição xDS
O Istiod mantém um canal gRPC com cada sidecar para distribuição de configuração (xDS). Com 500 serviços, assumindo uma média de 3 réplicas por serviço, são 1.500 conexões abertas. Cada atualização de certificado (que muda EndpointSlices e TLSSettings) dispara um push para todos os sidecars afetados. Se as renovações de certificado não forem escalonadas no tempo, o Istiod enfrenta um thundering herd que pode aumentar o tempo de propagação de configuração de milissegundos para dezenas de segundos.
Session cache compartilhado vs. por-réplica
O Envoy não compartilha cache de sessão TLS entre réplicas de um mesmo deployment. Cada pod tem seu próprio cache. Isso significa que um load balancer que distribui conexões entre 10 réplicas de um serviço pode fazer com que uma requisição seja servida pela réplica A (que tem a sessão em cache com o upstream) e a próxima pela réplica B (que não tem), forçando um cold handshake. Em alta disponibilidade, isso degrada a efetividade do session resumption de forma proporcional ao número de réplicas.
Rotação de certificados de curto prazo (short-lived certs)
A recomendação de segurança para ambientes zero trust é usar certificados com TTL de 24 horas ou menos. O SPIRE, quando configurado com TTL de 1 hora (configuração observada em implementações de compliance rigoroso), gera renovações constantes. Cada renovação invalida os session tickets emitidos com o certificado anterior, forçando cold handshakes em todas as conexões ativas. Em um cluster com 500 serviços e TTL de 1 hora, a rotação ocorre aproximadamente a cada 36-38 minutos (considerando a janela de renovação de 60% do TTL). Esse ciclo de invalidação de sessão mantém a taxa de cold handshakes artificialmente alta, mesmo em serviços com tráfego constante.
Mitigações reais: o que funciona em escala e o que é teatro
O que funciona de verdade:
A transição para arquitetura sidecarless (Istio Ambient ou Cilium com eBPF) é a mitigação estrutural mais eficaz. O dado de 8% de overhead no Istio Ambient contra 166% no Istio sidecar, ambos com mTLS ativo, não é uma diferença de implementação criptográfica, é uma diferença de arquitetura de proxy. A eliminação do duplo salto (iptables interception + proxy) remove a maior fonte de overhead não criptográfico que, em alta densidade, domina o custo total.
O escalonamento da renovação de certificados no tempo (certificate issuance staggering) é subestimado. Em vez de usar um único ClusterIssuer com schedule uniforme, distribuir os TTLs dos certificados de diferentes serviços ao longo do período de renovação reduz drasticamente os spikes de cold handshake. Uma implementação prática: usar o hash do nome do serviço como seed para calcular um offset de renovação dentro da janela de tempo disponível.
O pre-warming de conexão em eventos de scale-out é eficaz para o Cenário B descrito anteriormente. Antes de registrar uma nova réplica no load balancer, o readiness probe pode incluir uma etapa que estabelece conexões TLS com os principais upstream services, pré-aquecendo o session cache. Isso adiciona 2-3 segundos ao tempo de startup, mas elimina o spike de cold handshakes nas primeiras requisições reais.
O que é teatro (e não funciona):
Desabilitar mTLS em namespaces “internos de confiança” é a mitigação mais perigosa disfarçada de otimização. Em clusters de alta densidade, a distinção entre namespaces “internos” e “externos” é uma ilusão operacional que se desfaz no primeiro comprometimento de credencial. O overhead eliminado não justifica o risco.
Aumentar o TTL dos certificados para reduzir a frequência de renovação (e portanto de cold handshakes) é um trade-off de segurança que frequentemente não é explicitado como tal. Um TTL de 30 dias resolve o problema de performance, mas transforma um possível comprometimento de chave em um incidente de janela longa. A resposta correta é otimizar a arquitetura, não degradar a postura de segurança.
Timeline: como o problema tipicamente evolui em produção
Mês 1 — Service mesh habilitado em dev/staging com mTLS ativo.
Testes de carga em topologia pequena: latência "aceitável".
Mês 2-3 — Rollout para produção. Cluster cresce de 50 para 200 serviços.
P50 estável. P99 começa a subir silenciosamente.
Mês 4 — Time de produto reporta "lentidão intermitente" em fluxos críticos.
SRE investiga banco de dados, cache, GC da JVM. Sem conclusão.
Mês 5 — Auto-scaling agressivo durante campanha. Spike de P99 de 40ms → 180ms.
Post-mortem atribui ao scale-out de nós. Causa raiz: cold mTLS
handshakes em 30 réplicas novas simultaneamente.
Mês 6 — Cluster atinge 500+ serviços. Overhead de renovação de certificado
começa a aparecer como spikes regulares a cada ~40 minutos.
Ninguém correlaciona com o schedule do cert-manager.
Mês 7-8 — Investigação sistemática. Descoberta: overhead criptográfico acumulado
representa 18-22% da latência end-to-end em fluxos de 10+ hops.
Decisão: migração para arquitetura sidecarless ou refatoração
de topologia de chamadas para reduzir profundidade de cadeia.
Essa linha do tempo não é hipotética. É um padrão observado em organizações que crescem rápido em adoção de microserviços sem instrumentação adequada do plano de dados.
A decisão de arquitetura que ninguém quer ter
Em algum momento, qualquer equipe que opere 500+ serviços com mTLS universal vai enfrentar uma decisão binária: aceitar o overhead como custo de fazer negócio com zero trust, ou reconsiderar a granularidade dos serviços.
A segunda opção é tabu em muitas organizações porque vai contra a narrativa de que microserviços são sempre a resposta. Mas existe uma terceira via que raramente é discutida: a consolidação seletiva de serviços que têm alta coesão de domínio e baixo benefício de segurança no mTLS hop-a-hop. Se auth-service e session-service residem no mesmo namespace, são operados pelo mesmo time, e nunca precisam de políticas de tráfego independentes, a comunicação entre eles pode usar Unix Domain Sockets (quando colocalizados no mesmo pod) ou HTTP simples intra-pod sem passar pelo sidecar.
Essa não é uma recomendação de abandonar a arquitetura de microserviços. É uma lembrete de que granularidade de serviço e granularidade de identidade criptográfica são decisões ortogonais, e que equações podem ser separadas. O mTLS deve proteger fronteiras de domínio real, não cada função interna de um mesmo subdomínio que foi fragmentado além da necessidade operacional.
Conclusão: o custo está lá, só não está sendo medido
O overhead criptográfico acumulado do mTLS em clusters de alta densidade existe, é mensurável, e em condições realistas de deploy frequente e auto-scaling, pode representar dois dígitos percentuais da latência total end-to-end. Isso não é argumento contra mTLS, é argumento por uma instrumentação honesta e uma escolha de arquitetura de proxy que minimize o overhead não criptográfico que, ironicamente, representa a maior parcela do custo total.
Os números do arXiv 2411.02267 são claros: o Istio em modo sidecar acrescenta 166% de latência no P99 com mTLS, enquanto o Istio Ambient adiciona 8%. A criptografia é idêntica. A arquitetura é o que decide o custo. E a arquitetura é uma escolha feita por pessoas, não uma consequência inevitável de zero trust.
Quem já passou pela experiência de rastrear um P99 degradado por semanas e descobrir que a causa raiz era um thundering herd de cold mTLS handshakes durante renovação de certificado sabe exatamente do que este artigo trata. Quem ainda não passou, vai passar, se o cluster continuar crescendo sem uma estratégia de medição dedicada para o plano de dados criptográfico.



