
Por Gabriel Xavier Supervisor de Gestão e Arquitetura de Sistemas | Especialista em Governança de TI e Analytics
Às 3h11 da manhã do dia 20 de outubro de 2025, um ajuste de configuração, daqueles que qualquer engenheiro de plantão julgaria rotineiro, começou a rasgar silenciosamente o tecido da infraestrutura digital de 30% da nuvem mundial. Não houve alarme imediato. Não houve mensagem de erro dramática. Os queries DNS para o endpoint do DynamoDB na região US-East-1 simplesmente pararam de resolver. Retornavam SERVFAIL ou NXDOMAIN, como se o destino tivesse deixado de existir. Em menos de 80 minutos, Snapchat, Fortnite, Venmo, Roblox e centenas de serviços críticos ao redor do planeta estavam paralisados. O Downdetector registrou 17 milhões de relatos de usuários, um aumento de 970% em relação à linha de base diária média, em mais de 60 países.
O mais perturbador não foi a escala. Foi o fato de que aquela infraestrutura era classificada internamente como “highly available”.
Esse é o paradoxo central do DNS moderno: quanto mais sofisticada a arquitetura ao redor dele, mais invisível fica a fragilidade dentro dele. Balanceadores de carga multi-AZ, clusters Kubernetes com auto-scaling, pipelines de CI/CD auditados, tudo isso colapsa instantaneamente quando o sistema que traduz um nome em endereço para de responder. E a zona de falha quase nunca é onde o time de SRE olha primeiro.
A anatomia de uma falha que parece distribuída, mas não é
A promessa de alta disponibilidade repousa sobre um pressuposto implícito: que as dependências críticas do sistema são conhecidas e estão documentadas. Na prática, o que se acumula ao longo de anos de crescimento orgânico é um DAG (Directed Acyclic Graph) de serviços que, discretamente, desenvolveu ciclos. E o DNS vive exatamente nesses ciclos.
No caso da AWS em outubro de 2025, a lógica da falha seguiu um caminho que qualquer arquiteto de sistemas reconhecerá como teoricamente “impossível” na documentação oficial: o DynamoDB, incapaz de resolver seus próprios endpoints de API, interrompeu a capacidade do IAM de renovar tokens, afinal, o STS (Security Token Service) depende de chamadas de API que dependem de resolução DNS. Com o IAM comprometido, o EC2 perdeu acesso ao serviço de metadados de instância (IMDSv2). Lambda não conseguia bootstrapping. SQS acumulou mensagens não entregues. RDS disparou failover multi-AZ falso positivo, sobrecarregando a região vizinha us-west-2 com tráfego redirecionado.
O que parecia ser “apenas um problema de DNS” havia contaminado toda a cadeia de controle da nuvem.
A pesquisadora Agung Septiadi e seus colegas da Universidade de Nova Gales do Sul, em paper publicado em dezembro de 2025, documentaram exatamente esse padrão ao auditar a infraestrutura DNS autoritativa de serviços governamentais em múltiplos países: a maioria das arquiteturas “resilientes” na superfície apresenta, ao nível da zona autoritativa, dependência de um único provedor sem qualquer diversificação topológica real. O estudo revelou que 94% dos nameservers na zona raiz servem uma única zona, um número que sobe para proporções ainda maiores quando o escopo se estreita para domínios corporativos e governamentais de médio porte.
Resolver Público vs. autoritativo: dois modos de falhar, uma só consequência
Existe uma confusão persistente, e cara, entre o comportamento de falha de resolvers recursivos públicos e o de servidores autoritativos mal configurados. São vetores distintos, com assinaturas de falha distintas, e tratá-los como sinônimos é um dos erros mais comuns em arquiteturas que se autodeclaram resilientes.
A tabela abaixo mapeia as diferenças operacionais que importam em situações de crise:
| Dimensão | Resolver Público (ex: 1.1.1.1, 8.8.8.8) | Autoritativo Mal Configurado |
|---|---|---|
| Natureza da falha | Parcial, geográfica, transitória | Sistêmica, determinística, persistente |
| Sintoma observado | Timeout intermitente, latência alta | NXDOMAIN consistente, SERVFAIL em cascata |
| Impacto no TTL | Cache serve respostas antigas até expirar | Cache expira e não encontra resposta válida |
| Detectabilidade | Alta (monitoramento de latência) | Baixa (parece “serviço fora” no aplicativo) |
| Tempo de recuperação | Minutos (rota redundante assume) | Horas (propagação de correção + TTL expirando) |
| Causa raiz típica | Problema de roteamento BGP, overload de PoP | Registro ausente, SOA serial incorreto, delegação quebrada |
| Exemplo real (2025) | Cloudflare 1.1.1.1 — 14 jul. 2025 (62 min.) | AWS US-East-1 — 20 out. 2025 (4h+ de impacto) |
O incidente da Cloudflare de julho de 2025 ilustra bem o comportamento do resolver público. Uma configuração errada introduzida em 6 de junho, durante uma atualização de topologia de serviço que preparava um futuro recurso de localização de dados, ficou dormindo por 38 dias até ser ativada acidentalmente em uma segunda mudança em 14 de julho. Às 21h52 UTC, o tráfego global para o resolvedor 1.1.1.1 começou a cair. Às 22h54, após rollback e propagação completa, o serviço estava restaurado. 62 minutos de impacto. A causa técnica foi um sistema legado sem suporte a implantação progressiva, uma bomba-relógio que funcionava em produção há mais de um mês antes de detonar.
Já a falha de um autoritativo mal configurado segue uma lógica diferente: ela não é ruidosa. Ela é cirúrgica e silenciosa. Um registro NS apontando para um nameserver que não existe mais. Um SOA com serial desatualizado, impedindo transferências de zona. Uma delegação criada por um contratado que saiu da empresa há dois anos, apontando para um provedor de DNS descontinuado. Esses erros passam em todos os testes de disponibilidade básica porque o serviço técnico “continua de pé”, ele apenas entrega respostas erradas ou incompletas para uma fração das queries, dependendo de qual resolver recursivo a consulta atingiu primeiro.
O cenário de falha parcial que nenhum dashboard captura
Imagine uma zona autoritativa com quatro nameservers: ns1, ns2, ns3 e ns4. Três deles respondem normalmente. Um, ns3, foi migrado para um novo provider há três semanas, mas a entrada de delegação no registrador ainda aponta para o IP antigo. Cerca de 25% das queries globais, dependendo da distribuição dos resolvers recursivos e de seus algoritmos de seleção de nameserver, vão cair no ns3 inexistente. Essas queries vão expirar no timeout (geralmente 5 segundos por tentativa) antes de fazer fallback para os nameservers funcionais.
O resultado na prática? Um serviço com “99,8% de disponibilidade” nos monitores de uptime HTTP, mas com 25% das requisições sofrendo latências de 5 a 15 segundos antes de resolver, ou simplesmente falhando, dependendo das configurações de timeout da aplicação. Usuários móveis em redes com alta latência de base serão os primeiros a relatar erros. O time de suporte vai abrir tickets de “instabilidade inexplicável”. O time de infra vai olhar para os loadbalancers, para o banco de dados, para a CDN e o DNS autoritativo vai continuar quebrando silenciosamente, invisível no radar.
Este não é um cenário hipotético. É o padrão descrito em revisões pós-incidente de empresas que preferem não publicar post-mortems públicos.
A verdade sobre “highly available” e a zona que ninguém auditou
Existe uma desproporção profunda na maturidade de auditoria das diferentes camadas de uma arquitetura moderna. Times de infraestrutura dedicam ciclos extensos auditando políticas de IAM, configurações de Security Groups, réplicas de banco de dados, estratégias de backup e tratam o DNS como um artefato de configuração estático, alterado raramente, gerenciado via interface web do registrador ou do provedor de DNS, e raramente submetido a testes de resiliência estruturados.
O paper da Universidade de Nova Gales do Sul que mencionamos trouxe um dado que deveria ser mandatório em toda revisão de arquitetura: ao avaliar a infraestrutura DNS autoritativa de serviços governamentais de múltiplos países em uma escala de resiliência de 0 a 5, a média global ficou consistentemente abaixo de 3,5. Isso em sistemas que, por definição, precisam estar disponíveis 24 horas por dia, 7 dias por semana.
Para infraestruturas corporativas privadas, a situação tende a ser similar ou pior, porque há menos escrutínio regulatório.
As três configurações de zona que transformam “HA” em “single point of failure”
1. Todos os nameservers no mesmo ASN (Autonomous System Number)
Ter quatro nameservers com IPs diferentes mas todos hospedados no mesmo provedor de DNS, e portanto no mesmo ASN, significa que um problema de roteamento BGP afetando aquele ASN derruba todos eles simultaneamente. A diversidade aparente de IPs esconde uma dependência de transporte única. Para que a redundância seja real, os nameservers autoritativos precisam estar em ASNs distintos e preferencialmente em provedores com relações de peering independentes.
2. TTL configurado alto demais em registros que mudam frequentemente
Um TTL de 86.400 segundos (24 horas) em um registro A que aponta para a origem de uma CDN parece razoável em condições normais, reduz a carga sobre o autoritativo. Em condições de incidente, quando o IP de origem precisa ser alterado para um endereço de contingência, significa que 24 horas de cache envenenado serão distribuídas por todos os resolvers do planeta antes que a correção propague completamente. O custo de downtime acumulado durante esse período pode exceder por ordens de magnitude qualquer economia de latência que o TTL alto proporcionou.
O blog da NameSilo documentou casos em que TTLs acima de 3.600 segundos em registros críticos resultaram em tempos de recuperação de falha 4 a 8 vezes maiores do que o necessário. A recomendação prática, que poucos times seguem, é reduzir TTLs críticos para 300 segundos pelo menos 24 horas antes de qualquer migração planejada, e manter esse valor baixo como política permanente para registros de edge.
3. Zona de delegação nunca testada como unidade de falha independente
A delegação de zona é o mecanismo pelo qual o nameserver pai comunica ao mundo quais são os nameservers autoritativos de um domínio. Esse mecanismo depende de registros NS nos servidores do TLD (como .com, .br, .net), que são controlados pelo registrador, não pelo owner do domínio. Uma discrepância entre os NS no registrador e os NS configurados na zona autoritativa, o chamado “lame delegation”, resulta em falha de resolução para uma fração das queries que chegam “frias” ao TLD sem cache. Esse cenário é especialmente traiçoeiro porque sistemas de monitoramento que consultam os nameservers diretamente, e não via resolução recursiva completa, nunca vão detectar o problema.
Simulação de falha: o que acontece em cada cenário
Cenário A — resolver público falha parcialmente (comportamento tipo Cloudflare jul/2025)
Neste cenário, o autoritário está saudável. O problema está na camada de resolução recursiva: um dos resolvers públicos mais usados, digamos, o 1.1.1.1 está com problemas de roteamento em um PoP específico. Parte das queries é absolvida por PoPs alternativos com latência adicional. Outra parte falha silenciosamente.
O que o sistema experimenta:
A aplicação começa a ver timeouts de conexão esporádicos. O banco de dados continua respondendo. Os logs de aplicação mostram “connection refused” ou “dial tcp: i/o timeout”, sintomas que a maioria dos times vai associar primeiro a problemas de rede ou de backend, não de DNS. O tempo médio para identificar DNS como causa raiz, em incidentes desse tipo sem instrumentação explícita de DNS no stack de observabilidade, é tipicamente de 20 a 45 minutos, um intervalo suficiente para escalar o incidente desnecessariamente e gerar pressão organizacional desproporcional.
A recuperação é relativamente rápida quando identificada: ou o resolver alternativo assume naturalmente, ou a aplicação é reconfigurada para usar um resolver diferente. O dano principal é o tempo de detecção, não o tempo de correção.
Cenário B — autoritário mal configurado (comportamento persistente e silencioso)
Aqui o resolver público está saudável. O problema está na zona: um dos quatro nameservers autoritativos tem um registro SOA com número serial desatualizado, causando falha nas transferências de zona incrementais (IXFR). Esse nameserver está servindo uma versão da zona com 72 horas de atraso. Queries que chegam a ele recebem respostas que apontam para um endereço IP desativado durante uma migração de servidores.
O que o sistema experimenta:
Cerca de 25% dos usuários experimentam falhas ou redirecionamentos para um servidor inexistente. Os outros 75% funcionam normalmente. O sistema de monitoramento de uptime HTTP, que usa um resolver com o autoritativo correto em cache, marca o serviço como “online”. O sistema de APM mostra taxa de erro de 22-28%, que o time interpreta inicialmente como um bug de aplicação introduzido pelo último deploy. Um rollback é executado sem efeito. A investigação aprofundada começa. Horas se passam.
A diferença crítica entre os dois cenários está no padrão de afetação: no Cenário A, todos os usuários são afetados proporcionalmente e de forma transitória. No Cenário B, uma fração consistente dos usuários é afetada de forma determinística e persistente, exatamente o tipo de padrão que confunde diagnóstico e esconde a causa raiz por mais tempo.
O problema do TTL alto em arquiteturas de failover automático
Há uma ironia estrutural nas arquiteturas de DNS para failover: os mecanismos projetados para tornar o sistema mais eficiente, o cache de TTL, são exatamente os que tornam a recuperação de falha mais lenta e imprevisível.
Considere o seguinte diagrama de timeline de recuperação comparando duas configurações de TTL para um mesmo cenário de failover:
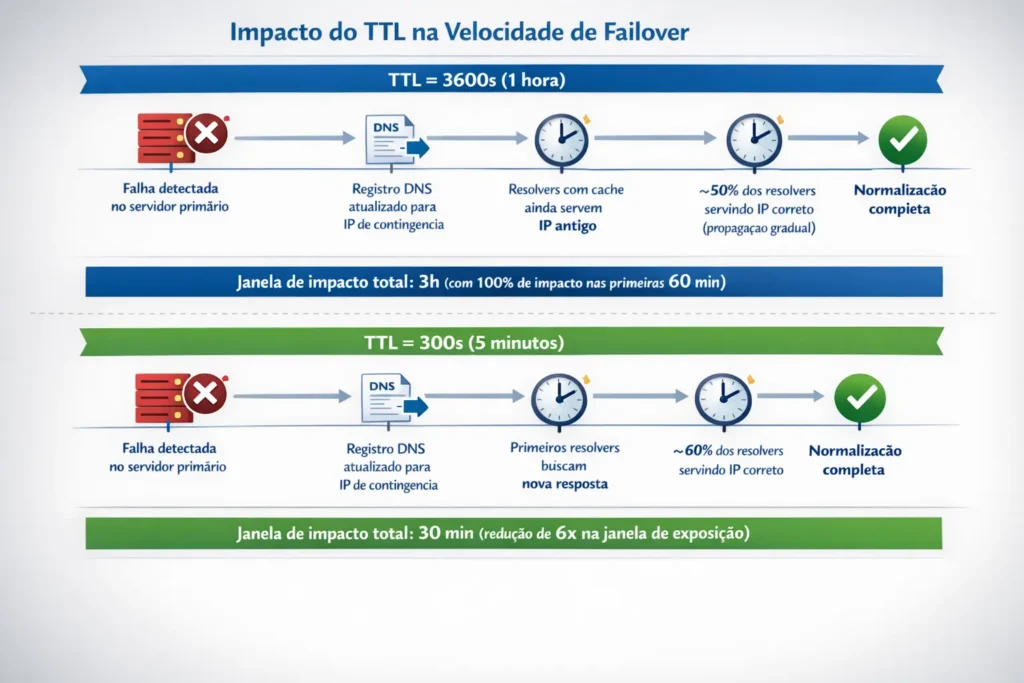
A diferença não é trivial. Em termos de impacto de negócio, para um serviço de e-commerce com receita de R$ 50.000/hora, essa diferença representa R$ 125.000 em receita recuperada. A contrapartida, um volume ligeiramente maior de queries ao autoritativo com TTL baixo é completamente absorvível por qualquer provedor de DNS gerenciado moderno.
O argumento frequentemente usado para justificar TTLs altos, “reduz a carga no autoritativo”, é válido em arquiteturas dos anos 2000, quando autoritativos eram servidores físicos gerenciados internamente. Em 2025, com provedores como Route 53, Cloudflare DNS e NS1 absorvendo bilhões de queries por dia com SLA de 100% de uptime, esse argumento perdeu a base técnica. O que persiste é inércia de configuração: ninguém tocou naquele TTL porque ninguém precisou, e ninguém revisou porque “está funcionando”.
A arquitetura que parece redundante e não é
Existe uma categoria de arquitetura que merece um nome próprio: redundância cosmética. É quando todos os elementos de alta disponibilidade estão presentes na documentação, nos diagramas e nas certificações, mas a cadeia de dependências real, quando rastreada até a raiz, converge em um único ponto não redundante.
No contexto DNS, o anti-padrão mais comum se manifesta assim:
Uma empresa opera dois data centers ativos com balanceamento de tráfego via DNS. Cada data center tem seus próprios servidores, banco de dados replicado, e sistemas de monitoramento independentes. O time de infraestrutura está orgulhoso da arquitetura. A análise de risco interna classifica o serviço como “sem single point of failure”.
Mas os dois registros A para os dois data centers estão em uma única zona DNS hospedada em um único provedor, sob uma única conta, com credenciais de acesso compartilhadas. Se o provedor de DNS tiver um outage ou se a conta for comprometida, ou se alguém acidentalmente deletar a zona, ambos os data centers tornam-se inacessíveis simultaneamente, independentemente de quantos 9s de disponibilidade cada um individualmente oferece.
O Cockroach Labs, em seu relatório de outages de 2025, descreveu exatamente este padrão ao analisar ambos os grandes outages da Cloudflare naquele ano: DNS, CDN, identidade e camadas de segurança tornaram-se “shared bottlenecks”, gargalos compartilhados, onde uma única falha em qualquer nó da cadeia derruba o conjunto. A sofisticação da arquitetura aumentou a complexidade sem reduzir proporcionalmente o risco, porque a superfície de dependência cresceu mais rápido do que os mecanismos de isolamento de falha.
O teste de resiliência DNS que nenhum runbook padrão inclui
Qualquer audit de resiliência DNS deveria incluir, no mínimo, os seguintes testes, que raramente aparecem em runbooks padrão:
Teste 1 — Simulação de NXDOMAIN por nameserver individual: Bloquear queries para cada nameserver autoritativo individualmente (um de cada vez) e verificar o comportamento do sistema. O tempo de fallback deve ser inferior ao timeout configurado nas aplicações cliente. Na maioria das arquiteturas não testadas, esse fallback leva entre 5 e 30 segundos, suficiente para derrubar conexões de curta duração.
Teste 2 — Validação de delegação via resolução recursiva completa: Não testar os nameservers diretamente. Testar via dig +trace dominio.com @8.8.8.8 para simular o caminho que um resolver recursivo frio percorre do root até o autoritativo. Discrepâncias entre este resultado e uma query direta indicam problemas de delegação que passam invisíveis em testes convencionais.
Teste 3 — Verificação de consistência entre nameservers: Todos os nameservers autoritativos de uma zona devem servir exatamente a mesma versão dos registros. Serial numbers diferentes indicam falha na transferência de zona. Ferramentas como dnstracer e zonemaster fazem essa verificação automatizadamente, mas são raramente integradas a pipelines de CI/CD.
Teste 4 — Injeção de TTL baixo antes de mudanças planejadas: Reduzir TTLs críticos para 60-300 segundos pelo menos 24 horas antes de qualquer alteração significativa de infraestrutura. Verificar que a mudança de TTL propagou globalmente antes de executar a migração. Reverter o TTL para o valor operacional apenas após confirmar a estabilidade da nova configuração.
Multi-provider DNS: a única resposta honesta para resiliência real
A recomendação técnica para eliminar DNS como single point of failure é bem estabelecida: utilizar múltiplos provedores de DNS autoritativos, com os nameservers de cada provedor listados como autoritativos para a zona. Se um provedor cai completamente, o outro continua respondendo.
A implementação prática, no entanto, enfrenta fricções reais que explicam por que a maioria das organizações não adota essa configuração mesmo sabendo que deveria:
Primeiro, a sincronização de zona entre provedores distintos requer uma solução de gerenciamento centralizado que abstrai as APIs distintas de cada provedor. Ferramentas como OctoDNS e dnscontrol resolvem esse problema ao tratar configurações de DNS como código, Infrastructure as Code para DNS, permitindo que uma única fonte de verdade (geralmente um repositório Git) sincronize automaticamente para múltiplos provedores.
Segundo, nem todos os provedores aceitam ser “secundários” em uma relação de transferência de zona AXFR/IXFR com um provedor primário concorrente. Alguns exigem que a zona seja gerenciada exclusivamente em sua plataforma. A arquitetura multi-provider efetiva requer provedores que suportem a operação como autoritativo secundário via TSIG (Transaction Signature) para transferências de zona autenticadas.
Terceiro, o custo. Manter zonas ativas em dois provedores premium doubles o custo de DNS. Para a maioria das organizações, esse custo é insignificante em relação ao risco, o Route 53 cobra aproximadamente US$ 0,50 por zona hospedada por mês, mas a aprovação orçamentária muitas vezes não acompanha o raciocínio de risco.
O resultado é que a maioria das empresas mantém redundância dentro de um único provedor (múltiplos nameservers, mas no mesmo ASN, sob a mesma conta), o que protege contra falhas de servidor individual mas não contra falhas de plataforma, exatamente o cenário que materializou nos outages de 2025.
O que os post-mortems não dizem
Os post-mortems públicos de outages como os de 2025 tendem a focar em “o que falhou” e “o que foi corrigido”. O que raramente aparece com a clareza necessária é “por que a falha ficou invisível por tanto tempo antes de detonar”.
No caso da Cloudflare de julho de 2025, a configuração problemática foi introduzida em 6 de junho e ficou dormindo por 38 dias. O sistema de configuração legado não tinha suporte a implantação progressiva — o que significa que a mudança foi aplicada de forma global e instantânea sem nenhum período de validação em ambiente reduzido. A questão que o post-mortem não responde diretamente é: quais outros sistemas legados com o mesmo padrão de risco ainda existem na mesma infraestrutura, e qual é a frequência com que são auditados ativamente?
No caso da AWS de outubro de 2025, o trigger foi uma “rotina de configuração” em um endpoint DynamoDB que desencadeou uma falha em cascata por toda a cadeia de dependências. O que o postmortem não documenta publicamente é quantas outras configurações similares existem na plataforma com o mesmo potencial de cascata, e se o processo de change management inclui análise de impacto em grafo de dependências antes de cada mudança.
Esta é a verdade que as organizações precisam incorporar nas suas revisões de arquitetura: o DNS não falha sozinho com frequência. Ele falha como resultado acumulado de decisões que pareciam seguras individualmente, um TTL não revisado aqui, uma delegação não testada ali, um nameserver migrado sem atualizar o registrador, um segundo provedor “para depois” que nunca foi implementado. O incidente é o ponto onde essas decisões convergem.
Checklist de auditoria DNS para arquiteturas que se dizem resilientes.
A seguinte estrutura de auditoria representa o mínimo necessário para que uma arquitetura possa legitimamente usar o rótulo de “DNS resiliente”. Não é exaustiva é o piso, não o teto.
| Camada | Item de Auditoria | Risco se Ignorado |
|---|---|---|
| Delegação | NS no registrador coincide com NS na zona? | Lame delegation — 25%+ das queries falham |
| Delegação | Todos os nameservers listados respondem queries? | Timeout parcial em 1/n queries |
| Topologia | Nameservers em ASNs distintos? | Falha de BGP derruba toda a redundância |
| Topologia | Nameservers em provedores distintos? | Outage de plataforma elimina toda redundância |
| Zona | Todos os nameservers servem o mesmo serial SOA? | Cache inconsistente, respostas divergentes |
| TTL | TTLs críticos abaixo de 300s? | Janela de impacto de failover estendida |
| DNSSEC | Assinatura de zona válida e com prazo de renovação monitorado? | Falha de validação em resolvers DNSSEC-aware |
| Monitoramento | DNS testado via resolução recursiva completa (+trace)? | Problemas de delegação invisíveis |
| Monitoramento | Tempo de resposta por nameserver individual monitorado? | Falha parcial não detectada |
| Processo | TTL reduzido antes de mudanças planejadas? | Janela de impacto desnecessariamente longa |
| Processo | Zona em controle de versão (IaC)? | Mudanças não auditadas, rollback manual |
A perspectiva do responsável técnico que vai ser acordado às 3h da manhã
Não existe arquitetura que elimine o risco de falha de DNS. Existe arquitetura que reduz a probabilidade, limita o raio de explosão e, principalmente, encurta o tempo entre a falha e a detecção, entre a detecção e o diagnóstico, e entre o diagnóstico e a recuperação.
A diferença entre uma organização que sobrevive a um outage de DNS com 15 minutos de impacto e uma que sobrevive com 4 horas não está na sofisticação dos sistemas de computação. Está na qualidade da auditoria da zona DNS, na maturidade do processo de change management para infraestrutura de resolução de nomes, e na cultura de tratar DNS como o que ele realmente é: a camada mais crítica e menos testada de qualquer arquitetura distribuída.
O próximo outage que vai acordar alguém às 3 da manhã provavelmente já está configurado em alguma zona mal auditada, em algum TTL alto que ninguém revisou, em alguma delegação que foi atualizada no servidor mas não no registrador. Ele vai se disfarçar de problema de rede, de bug de aplicação, de instabilidade de banco de dados, até que alguém tenha a disciplina de executar um dig +trace antes de qualquer outra investigação.
Quando esse momento chegar, as organizações que fizeram a auditoria vão resolver em minutos. As que não fizeram vão passar horas olhando para o lugar errado.



