
Por Flank Manoel da Silva Especialista Sênior Full Stack | Analista de Infraestrutura e Performance
Ninguém gosta de ouvir isso em uma reunião: o problema não é o seu código, não é o cloud provider, não é o protocolo de consenso. O problema mora a 9.500 quilômetros de distância e viaja a dois terços da velocidade da luz dentro de um cabo submarino. Quando você decidiu colocar um commit síncrono entre São Paulo e Londres, você assinou um contrato com a física e a física nunca negocia SLA.
Este artigo não vai explicar o que é replicação síncrona. Se você chegou até aqui buscando isso, há materiais mais adequados. Aqui o ponto de partida é outro: você já sabe o que é, já leu o CAP Theorem e agora está sentado na frente de um gráfico de latência P99 que não fecha com a promessa que você fez ao time de produto. Vamos trabalhar a partir daí.
O limite que nenhum tuning resolve
Existe uma fronteira que nenhuma configuração de buffer, nenhum ajuste de wal_level no PostgreSQL, nenhum parâmetro de rpl_semi_sync_master_timeout no MySQL atravessa: a latência mínima imposta pela distância física.
A velocidade da luz no vácuo é 299.792 km/s. Dentro de uma fibra óptica, por conta do índice de refração do vidro, em torno de 1,46, esse valor cai para aproximadamente 200.000 km/s, ou seja, cerca de 5 microssegundos por quilômetro de cabo percorrido em uma direção. O Round-Trip Time (RTT) teórico mínimo, considerando apenas ida e volta, é o dobro disso.
O problema real é que cabos submarinos não seguem linha reta. A rota entre São Paulo (sa-east-1) e a região de Frankfurt (eu-central-1) via cabo submarino percorre algo próximo de 10.000 km de extensão de cabo efetivo, com acréscimos de roteamento, repetidores, e pontos de presença intermediários. O RTT teórico mínimo nessa rota fica em torno de 100 ms e o RTT real observado em benchmarks de cloud (cloudping.co, Kentik Cloud Latency Map) oscila entre 170 ms e 220 ms dependendo da hora do dia e da carga nos backbones.
Agora pense no que acontece quando você exige um commit síncrono nessa rota.
O custo real de um commit síncrono intercontinental
Em replicação síncrona, o nó primário não retorna sucesso ao cliente até receber confirmação do nó secundário. Isso significa que cada transação carrega embutida, no mínimo, um RTT completo. Não é uma média, é um piso físico.
A tabela abaixo mostra os RTTs reais medidos entre pares de regiões intercontinentais, a penalidade mínima por commit síncrono, e a taxa de transações por segundo (TPS) máxima teoricamente possível apenas por conta da latência de rede, ignorando processamento, I/O e contenção de lock:
| Par de Regiões | RTT Médio Observado | RTT Teórico Mínimo (física) | TPS Máximo (somente latência de rede) |
|---|---|---|---|
| São Paulo → N. Virgínia (us-east-1) | ~130 ms | ~90 ms | ~11 TPS |
| São Paulo → Frankfurt (eu-central-1) | ~195 ms | ~100 ms | ~10 TPS |
| São Paulo → Tóquio (ap-northeast-1) | ~290 ms | ~170 ms | ~6 TPS |
| N. Virgínia → Londres (eu-west-2) | ~80 ms | ~70 ms | ~14 TPS |
| N. Virgínia → Tóquio (ap-northeast-1) | ~150 ms | ~110 ms | ~9 TPS |
| Frankfurt → Singapura (ap-southeast-1) | ~160 ms | ~90 ms | ~11 TPS |
O número que mais incomoda nessa tabela não é o RTT, é a coluna de TPS. Um sistema que precisa de consistência forte global entre São Paulo e Tóquio está arquiteturalmente limitado a cerca de 6 transações por segundo por thread de commit síncrono, antes mesmo de qualquer trabalho real acontecer. Qualquer pico de carga acima disso constrói fila. A fila vira latência. A latência vira timeout. O timeout vira incidente.
Anatomia de um benchmark de commit distribuído
Para tornar isso concreto, vale detalhar o que acontece quando você instrumenta um benchmark de commit síncrono entre regiões intercontinentais com workload OLTP típico.
O setup do teste
Considere o cenário usado em análises recentes de arquitetura distribuída: um nó primário em us-east-1 (N. Virgínia), réplicas síncronas em eu-central-1 (Frankfurt) e ap-northeast-1 (Tóquio), e um cliente de benchmark emitindo transações a partir do primário. O protocolo testado é uma variação de Two-Phase Commit com acknowledgment de quorum majoritário, o mesmo mecanismo base do Google Spanner e do protocolo de replicação do Aurora DSQL, lançado no re:Invent 2024.
O que os números revelam
Com commits síncronos exigindo acknowledgment de todas as réplicas (modo mais conservador, equivalente ao synchronous_commit = remote_apply no PostgreSQL ou ao Maximum Protection do Oracle Data Guard), os resultados seguem um padrão previsível e perturbador:
No mesmo AZ: 0,3 a 5 ms por commit. Throughput alto, latência baixa.
Cross-AZ na mesma região: 1 a 5 ms adicionais. Ainda gerenciável.
Cross-region no mesmo continente: 30 a 80 ms de RTT. Performance cai 60 a 80% em relação ao baseline local.
Intercontinental: 100 a 300 ms de RTT. O throughput não é mais medido em percentual de degradação — é medido em unidades absolutas de TPS que ficam na casa de um dígito por thread sequencial.
Quando o quorum é majoritário (2 de 3 réplicas), e a réplica mais próxima é Frankfurt (80 ms de RTT a partir de N. Virgínia), o sistema opera razoavelmente. A réplica de Tóquio fica fora do caminho crítico. É exatamente aí que mora a armadilha: o arquiteto assume que a “consistência global” está garantida porque há três réplicas, mas na prática o dado só chegou de forma síncrona a dois terços do mundo.
O problema da cauda de latência (P99 e P99.9)
Quem só olha para a mediana (P50) de latência está tomando decisões com dados incompletos. O P99.9 em links intercontinentais pode ser 3 a 5 vezes maior que o P50, por conta de congestionamento em backbones submarinos, retransmissões TCP por perda de pacote em cabos de alta latência, e janelas de congestionamento TCP que nunca se abrem completamente a distâncias continentais (um link de 1 Gbps com 40 ms de RTT opera a menos de 13 Mb/s efetivos devido às limitações do algoritmo de controle de congestionamento TCP sem tuning agressivo de RWND).
Um sistema que tem P50 de 180 ms em commits síncronos São Paulo → Frankfurt vai ter P99.9 próximo de 800 ms a 1 segundo em momentos de congestionamento de backbone. Se o timeout da sua aplicação for de 500 ms, você vai ver erros de timeout que não aparecem nos testes de carga controlados, aparecem em produção, às 18h de uma sexta-feira, quando o volume de transações está no pico.
Cenário A vs. Cenário B: quando a sincronia é justificável (e quando não é)
- Cenário A — Fintech com regulação de dados soberana
Uma fintech brasileira com operação regulada pelo Banco Central precisa manter dados de transações financeiras em território nacional, mas quer redundância geográfica real para sobreviver a uma falha de datacenter em São Paulo. A segunda região é São Paulo 2 (quando disponível) ou, como alternativa atual no AWS, uma combinação de zonas de disponibilidade dentro da mesma região.
Nesse cenário, replicação síncrona entre AZs na mesma região é mandatória, razoável e performática. O RTT entre AZs na região sa-east-1 é de 1 a 4 ms, dentro da janela que Oracle, PostgreSQL e MySQL documentam como viável para remote_write síncrono sem degradação crítica de throughput.
Adicionar uma réplica síncrona em us-east-1 para “ter uma cópia fora do país” nesse contexto não só viola a soberania de dados exigida pela regulação como impõe uma penalidade de ~130 ms por commit sem nenhum benefício regulatório. A resposta correta aqui é replicação assíncrona cross-border com RPO explicitamente acordado na faixa de segundos, não zero.
- Cenário B — SaaS global com consistência de sessão
Um SaaS com usuários ativos nos EUA, Europa e Ásia-Pacífico precisa garantir que um usuário que escreve dados em São Paulo e em seguida faz uma leitura a partir de Frankfurt veja seus próprios dados, o modelo de consistência chamado de “read your own writes” ou “session consistency”.
A tentação aqui é configurar replicação síncrona entre todas as regiões. O custo é demolidor. A solução correta é uma combinação de roteamento de sessão baseado em afinidade de origem, replicação assíncrona com lag monitorado ativamente (target: sub-2 segundos em condições normais), e um mecanismo de “read-after-write” que roteia a leitura de volta ao primário nos primeiros N segundos após uma escrita, independentemente de onde o cliente está.
O Azure Cosmos DB resolve isso com o modelo de consistência “Session”, que garante read-your-own-writes sem exigir sincronismo global. O AWS DynamoDB Global Tables com consistência eventual usa tokens de sessão para o mesmo efeito. Nenhum deles força um RTT intercontinental no caminho crítico de escrita.
A distinção entre esses dois cenários é o tipo de pergunta que separa quem projeta sistemas distribuídos de quem apenas os implanta.
O que o Google fez (e por que você provavelmente não pode replicar)
O Google Spanner é frequentemente citado como prova de que consistência forte global é possível sem pagar o preço da latência. Essa leitura é parcialmente correta e amplamente mal compreendida.
O Spanner usa o TrueTime, um sistema de sincronização de relógio distribuído baseado em receptores GPS e relógios atômicos instalados em todos os datacenters do Google. O TrueTime não elimina a latência de rede, ele permite que o Spanner atribua timestamps de commit com intervalos de incerteza de 1 a 7 milissegundos, o que possibilita uma forma de consistência externa (external consistency) mais forte que linearizabilidade tradicional.
O mecanismo de “commit wait” do Spanner força cada transação a aguardar até que o intervalo de incerteza do TrueTime tenha passado antes de liberar o resultado ao cliente. Isso introduz uma latência adicional de 1 a 14 ms por commit, um custo deliberado para garantir que a ordem global de commits seja observável de forma consistente por qualquer leitor em qualquer datacenter.
O que o Spanner não faz é eliminar a física. Transações que envolvem partições em múltiplas regiões ainda precisam de ao menos 1 RTT para coordenação, o que, em escala intercontinental, é 100 a 300 ms. A latência documentada pelo Google para reads com staleness zero em Spanner multi-regional é de 15 ms para leituras de regiões próximas e sobe significativamente para configurações verdadeiramente intercontinentais.
O que o Google tem que praticamente ninguém mais tem: infraestrutura de rede proprietária com cabos submarinos dedicados, roteamento de baixo nível otimizado para minimizar overhead de protocolo, e décadas de engenharia específica para reduzir o overhead acima do piso físico. A diferença entre o RTT teórico (física pura) e o RTT real em infra do Google é menor do que em qualquer cloud pública disponível no mercado. Mas o piso físico existe para o Google também.
O protocolo de Consenso não é o problema, é o mensageiro
Raft e Paxos são frequentemente apontados como fontes de latência em sistemas distribuídos. É uma atribuição equivocada. O protocolo de consenso acrescenta overhead de coordenação, em implementações bem otimizadas, esse overhead é de microsegundos a poucos milissegundos dentro de uma mesma região. O que domina a latência intercontinental não é o protocolo: é o RTT da rede, que o protocolo apenas reflete.
Um líder Raft em us-east-1 precisa enviar um log entry para a maioria dos followers antes de marcar o commit como concluído. Se dois dos três followers estão na mesma região, o quorum é atingido localmente. Se os followers estão em eu-central-1 e ap-northeast-1, o quorum mínimo exige esperar o mais rápido dos dois, que ainda é Frankfurt, com ~80 ms de RTT.
A recente pesquisa sobre o protocolo Tiga (arXiv, 2025) propõe commitar transações dentro de 1 WRTT (Wide-Area Round-Trip Time) para uma ampla gama de cenários, reduzindo o overhead de coordenação acima do RTT básico. Isso é progresso real, mas “dentro de 1 WRTT” ainda significa que, entre São Paulo e Tóquio, você está dentro de ~290 ms.
O Aurora DSQL, apresentado no re:Invent 2024 da AWS, usa uma arquitetura de “adjudicadores” distribuídos com protocolo de commit otimizado que busca reduzir o número de round-trips necessários para coordenação. O resultado documentado é uma penalidade de 15 a 100 ms por commit cross-region, dependendo das regiões envolvidas. Ainda é física, mas é física com menos overhead de protocolo.
O que ninguém coloca no diagrama de arquitetura
TCP usa controle de congestionamento baseado em janela deslizante. Em um link com 200 ms de RTT, mesmo sem perda de pacote, a janela de congestionamento demora dezenas de round-trips para atingir o tamanho que maximiza o throughput. Em links intercontinentais com eventos de perda esporádica, que ocorrem em cabos submarinos com frequência maior do que em links terrestres, o throughput efetivo de um único fluxo TCP raramente atinge o que a largura de banda do link permitiria.
Isso tem impacto direto em replicação síncrona de lotes grandes. Um commit de transação com payload de 1 MB entre São Paulo e Frankfurt não leva apenas 1 RTT, leva vários RTTs para que a janela TCP se expanda o suficiente para transmitir o payload inteiro. O protocolo de replicação precisa ser consciente disso ou usará múltiplas conexões TCP paralelas para contornar o problema, o que tem seu próprio custo em overhead de coordenação.
O efeito do horário do dia nos cabos submarinos
Backbones submarinos compartilham capacidade com todo o tráfego de internet de uma rota. O RTT entre São Paulo e Europa às 14h do horário de Brasília (11h em Londres, horário de pico de tráfego europeu) é mensurável e consistentemente maior do que o mesmo RTT às 3h da manhã. A diferença pode ser de 20 a 40 ms adicionais em períodos de congestionamento de backbone.
Sistemas de replicação síncrona intercontinental que funcionam dentro do SLA durante testes noturnos falham no P99 em horários de pico, não porque algo quebrou, mas porque a física mudou sutilmente. O sistema estava operando na margem desde o início.
A ilusão da disponibilidade global
Um arquiteto coloca três réplicas em três continentes e declara o sistema “globalmente disponível”. O que ele não documentou: em modo de replicação síncrona com quorum de maioria (2 de 3), qualquer partição de rede que isole o primário das duas réplicas ao mesmo tempo torna o sistema indisponível para escritas. Partições simultâneas em dois links intercontinentais são raras mas não impossíveis, eventos de corte de cabo submarino acontecem múltiplas vezes por ano em rotas de alta demanda como Atlântico Norte e Transpacífico.
O CAP Theorem não é uma teoria acadêmica distante. Ele aparece como uma janela de indisponibilidade de 2 a 8 horas enquanto operadoras de cabo reparam a fibra cortada.
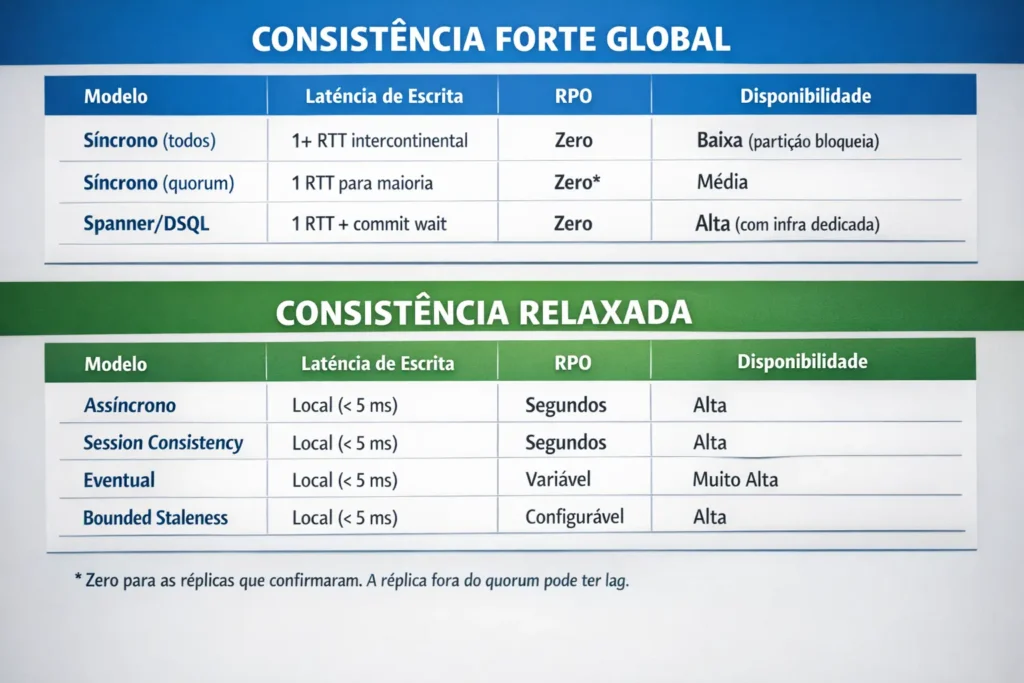
O que esse diagrama revela com clareza cirúrgica: todo o eixo de “consistência forte global” paga a conta da latência intercontinental. Não existe consistência forte global com latência de escrita local. Quem afirmar o contrário está vendendo uma abstração que esconde o custo, mas o custo existe, e está na conta do cloud provider ao fim do mês ou no gráfico de P99 do seu APM.
O modelo mental que muda a conversa com o time de produto
A discussão técnica sobre RTT e consistência frequentemente encalha porque o time de produto não tem contexto para avaliar as concessões. A conversa produtiva não é “replicação síncrona adiciona 200 ms de latência”, é uma questão de negócio:
Qual é o custo, em dinheiro ou em reputação, de um usuário em Frankfurt ler um dado desatualizado por até 2 segundos após uma escrita feita em São Paulo? Se a resposta for “nenhum impacto real”, eventual consistency com lag monitorado é a resposta correta. Se a resposta for “isso pode resultar em uma decisão de crédito errada em um sistema bancário”, a consistência forte é necessária e o sistema precisa ser arquitetado para pagar o preço que a física cobra.
O problema quase nunca é técnico em sua raiz. É uma ausência de negociação explícita sobre o que “consistência” significa no contexto do produto. Sistemas como o Azure Cosmos DB oferecem cinco níveis de consistência configuráveis exatamente porque reconhecem que a resposta correta depende do contexto, e que forçar consistência forte onde a eventual basta desperdiça recursos e entrega uma experiência pior por causa dos timeouts.
Conclusão: o que fazer com essa realidade
A física não vai mudar. A velocidade da luz na fibra óptica é uma constante que engenheiros de software precisam tratar com o mesmo respeito que engenheiros civis tratam a gravidade. Você não projeta uma ponte ignorando a gravidade, você projeta conhecendo-a e criando estruturas que trabalham com ela, não contra ela.
O que muda com o tempo é quanto overhead acima do piso físico você consegue eliminar. O Google reduziu esse overhead mais do que qualquer player do mercado com o TrueTime e a infra dedicada. O Aurora DSQL está reduzindo com o protocolo de adjudicadores. O Tiga propõe chegar a 1 WRTT de overhead total. São avanços reais, mas todos eles entregam “mais próximo do piso físico”, nunca “abaixo do piso físico”.
A escolha arquitetural correta para sistemas distribuídos globais não é “síncrono ou assíncrono”. É: qual o menor custo de consistência que este caso de uso específico consegue aceitar, dado o que a física permite? Responder a essa pergunta com precisão e documentar a resposta de forma que o time de produto, o time de infraestrutura e o time de compliance estejam alinhados, é o trabalho real de um arquiteto de sistemas distribuídos.



