
Por Gabriel Xavier Supervisor de Gestão e Arquitetura de Sistemas | Especialista em Governança de TI e Analytics
A verdade que a maioria dos engenheiros brasileiros descobre tarde demais: você pode estar gastando 10 vezes mais com chamadas de API do que com o armazenamento real. Em reais, isso significa faturas de dezenas de milhares por mês quando deveria ser centenas. Isso acontece quando milhões de arquivos pequenos vivem no seu bucket, e cada acesso custa centavos que se multiplicam rapidamente.
O cenário que ninguém prepara você para: 10 milhões de miniaturas em S3
Imagina a situação: você tem uma plataforma de e-commerce com 10 milhões de imagens de produtos. Cada uma tem três versões: original (2MB), miniatura (150KB) e thumbnail (30KB). Isso são 30 milhões de objetos no total, ocupando aproximadamente 70GB de espaço. A fatura mensal de armazenamento? R$ 8,29 apenas em storage. Parece um custo negligenciável, porque é.
Mas aí vem a operação: quando um cliente acessa seu site, o catálogo faz 50 requisições GET para carregar as imagens de miniatura de uma página. Com 100 mil visitantes por dia, você está fazendo 5 bilhões de GETs por mês. O custo? R$ 10.300,00 apenas em requisições GET por mês. Se incluir PUTs quando produtos são atualizados (digamos 50 mil produtos novos/mês = 150 mil PUTs), adicione R$ 3,87. O custo operacional explosivamente ultrapassou o armazenamento.
Realidade do mundo real: Em operações com milhões de objetos pequenos, o custo de API pode ser 1.240 vezes maior que o custo de armazenamento mensal. Isso não é exagero, é matemática simples com dados reais em reais brasileiros.
Por que as APIs dominam a conta: a anatomia do custo real em reais
O AWS S3 cobra por duas dimensões completamente distintas, e a indústria dramaticamente subestima uma delas.
Dimensão 1: Armazenamento (o que todos pensam que é caro)
Você paga R$ 0,12 por GB armazenado em S3 Standard por mês na região sa-east-1 (São Paulo). Se você tem 1TB, paga R$ 123,52 mensais. Se tem 1PB, paga R$ 123.520. Essa é uma variável previsível e linear. A maioria dos arquitetos negocia isso, provisiona certa capacidade e segue adiante.
Mas eis o problema: objetos pequenos não economizam espaço na fatura de armazenamento. Você pode ter 1 KB em 1 milhão de arquivos, ou 1GB em 1 arquivo. Ambos custam o mesmo em storage, mas não em requisições.
Dimensão 2: Operações de API (o verdadeiro vilão)
Aqui está o que a documentação não deixa claro com força suficiente: cada operação de API, ler um arquivo, escrever, deletar, listar, é uma transação cobrada separadamente.
Tipo de Operação Custo por 1.000 Requisições (USD) Custo em Reais Custo por 1 Milhão GET (leitura) $0,0004 R$ 0,0021 R$ 2,10 PUT/POST/COPY (escrita) $0,005 R$ 0,0262 R$ 26,21 DELETE $0,0004 R$ 0,0021 R$ 2,10 LIST (listagem) $0,005 R$ 0,0262 R$ 26,21
Note que PUT custa 12,5 vezes mais que GET. Uma operação simples de escrita custa mais que dez leituras. E quando você tem pipelines que processam objetos em massa, transformações, compactações, migrações, cada uma gera múltiplas requisições que multiplicam rapidamente seu gasto em reais.
Simulação prática
- Cenário A: processamento de log com compactação diária
Sua aplicação gera 500 mil logs por hora. Cada log é um arquivo separado (1KB cada). Ao final do dia, você tem 12 milhões de arquivos. À noite, um job de compactação lê todos eles, consolida em 100 arquivos compactados e deleta os originais.

O custo operacional é 85 vezes maior que o custo de armazenamento. Isso é uma proporção que a maioria dos times não consegue explicar para o CFO porque nunca separou os números dessa forma.
Como esse cenário piora ainda mais
Se você não consolidar esses logs e deixar 12 milhões de objetos dormindo no bucket, o custo mensal de armazenamento sobe para R$ 1.441 (12M × 1KB × R$ 0,12/GB), enquanto as operações continuam custando os mesmos R$ 1.518 em processamento. De repente, storage e operações ficam numa proporção equilibrada, mas o total continua extremamente alto.
A lição: consolidar arquivos pequenos não é um “nice-to-have” é uma obrigação financeira.
- Cenário B: CDN com cache inválido
Você tem 500 mil imagens em S3 servidas por CloudFront. A taxa de cache hit é 85%, mas os 15% que caem (75 mil requisições diárias para origem) vêm de padrões de acesso aleatórios. Além disso, quando você faz uma atualização de imagem, toda a URL muda, invalidando o cache manualmente. Isso gera picos de requisições não-previstos.
Num mês com 75 mil GETs/dia + um pico de invalidação que gera 2 milhões de GETs adicionais (2 dias com tráfego anormalmente alto):

Se você tem 500 mil imagens e cada uma pesa 1MB em média, o armazenamento custa R$ 59.200/mês. Neste caso, as operações são negligenciáveis. Mas se você tem 50 milhões de imagens pequenas (30KB cada), cenário real em plataformas de UGC, temos R$ 177.600/mês em storage, e as operações disparadas por padrões de acesso imprevisíveis podem facilmente ultrapassar esse número.
- Cenário C: migração de dados com leitura repetida
Você está migrando 100 milhões de objetos de S3 para DataSync de um data center local. O AWS DataSync lê cada objeto uma vez, mas o seu sistema de monitoramento interno verifica o status de cada transferência lendo metadados do S3. Isso gera 100M leituras de LIST + 100M leituras de GET.
Se cada transferência leva 2 semanas, você está fazendo leituras adicionais redundantes todos os dias para verificar progresso.

Esse é o tipo de custo que passa despercebido porque ninguém está analisando a fatura em granularidade de operação. Você vê uma fatura de R$ 15.000 em S3, mas não sabe se R$ 10.000 são armazenamento ou operações.
A matemática brutal: arquivos pequenos vs. consolidados
Vamos usar números que a maioria das documentações técnicas ignora: o custo real de fragmentação de dados em reais brasileiros.

Esse não é um cálculo teórico. É o que observamos em ambientes reais onde pequenos arquivos, logs, eventos, metadados, proliferam sem controle. A diferença em reais é simplesmente brutal.
Leia também: Por que seu pacote DNS viaja milhares de quilômetros além do necessário: o lado oculto do Anycast
A curva de custo operacional por padrão de acesso
Existem três padrões de acesso que ditam o custo operacional real:
Padrão 1: escrever uma vez, ler muitas (WORM)
Logs, backups, dados históricos. O custo de API é dominado por leitura. Com 1 bilhão de leituras/mês em dados arquivados, você paga R$ 2.100. É uma proporção onde GET ainda é o vilão, mas pelo menos é previsível em reais.
Padrão 2: leitura-escrita equilibrada
Bancos de dados de objetos, cache de sessões. Você faz PUTs e GETs em proporção similar. Aqui, PUT dominará a fatura porque custa 12x mais. 10 milhões de PUTs + 100 milhões de GETs = R$ 21,00 em GETs + R$ 262,10 em PUTs = R$ 283,10 total.
Padrão 3: múltiplas leituras com processamento em pipeline
Transformações de dados, ETL, machine learning. Cada objeto é lido várias vezes durante transformação. 100 milhões de objetos × 3 leituras (original, processamento intermédio, validação) = 300M GETs = R$ 630,00/mês. Aqui, consolidar objetos antes de processar reduz custos em 90%.
A verdade hiperespecífica: o que a AWS não enfatiza
Aqui está o detalhe que diferencia engenheiros senior de iniciantes: a AWS não cobra por armazenamento mínimo por objeto. Mas a estrutura do S3 foi projetada para objetos que custam centavos para armazenar, não milhões de miniaturas.
Problema 1: sem limite mínimo de tamanho, mas custo mínimo de operação
Você pode colocar um arquivo de 1 byte no S3. Ele custará R$ 0,12 × (0,000001 GB) = R$ 0,00000012 por mês, negligenciável. Mas acessá-lo uma vez custa R$ 0,0021 ÷ 1K = R$ 0,0000021 por requisição.
Se você tem 1 bilhão desses arquivos de 1 byte, o armazenamento custa R$ 0,12 mensais (porque são 1MB no total). Mas acessar cada um uma vez custa R$ 2.100. O custo operacional é 17.500 vezes maior que o custo de armazenamento.
Problema 2: LIST é a operação mais cara e invisível
Uma operação LIST bucket é cobrada como PUT (R$ 0,0262 por 1K = R$ 26,21 por 1 milhão). Mas muitos engenheiros usam LIST em loops ou processamento paralelo sem perceber quantas operações estão contabilizando.
Se você faz um LIST que retorna 1.000 objetos, é contado como 1 operação. Mas se faz LIST com prefixo que retorna 10 objetos, ainda é 1 operação. A armadilha: não há limite de quantos objetos um LIST retorna antes de ser cobrado como múltiplos LISTs.
Configurar um S3 Inventory (que custa R$ 0,013 por 1 milhão de objetos) para gerar manifesto de listing é 2.000 vezes mais barato que fazer LIST iterativos todos os dias.
Problema 3: replicação entre regiões multiplica custos de operação
Se você usa S3 Cross-Region Replication (CRR) para alta disponibilidade, cada PUT em uma região gera um PUT replicado em outra. Sua fatura de PUTs é multiplicada por número de regiões + 1 (original).
Com 10 milhões de PUTs/mês em 2 regiões, você paga por 20 milhões de PUTs (10M originais + 10M replicados), não 10M. Isso adiciona R$ 262,10/mês apenas em operações de replicação.

Estratégias de otimização: além doóbvio
- Estratégia 1: consolidação inteligente com particionamento
Em vez de armazenar 1 objeto = 1 arquivo, agrupe objetos logicamente em arquivos compostos (tar, parquet, proto com índices). Isso reduz operações em até 1.000x.
Para logs, em vez de 12 milhões de arquivos de 1KB/dia, compacte em 100 arquivos de 120KB/dia. O custo de leitura cai de R$ 25,30/dia para R$ 0,27/dia. O custo de escrita permanece negligenciável. A economia é brutal.
- Estratégia 2: cache local com invalidação inteligente
Se você serve conteúdo através de CloudFront, mantenha um cache local de objetos frequentemente acessados. Isso reduz GETs em S3. Com cache hit de 95%, suas requisições de origem caem para 5% do total.
Se você tinha 500M requisições/mês (custando R$ 1.050), com cache de 95% cai para 25M (custando R$ 52,50). A economia de R$ 997,50/mês justifica manter um cache SSD de 100GB local (~R$ 260/mês).
- Estratégia 3: S3 Intelligent-Tiering para padrões de acesso imprevisíveis
Se você não consegue prever qual dados será acessado com frequência, use S3 Intelligent-Tiering. Ele move dados automaticamente entre camadas conforme padrão de acesso muda, cobrando apenas pela transição (R$ 0,052 por 1K transições).
Para 100 milhões de objetos que você não sabe se serão acessados, Intelligent-Tiering custa marginalmente mais em storage (~R$ 0,031 por GB vs. R$ 0,12 Standard), mas economiza em leituras quando objetos se movem para camadas mais baratas.
- Estratégia 4: monitoramento granular de custos
Configure CloudWatch para monitorar número de operações por tipo de requisição. Crie alertas quando PUTs excedem limiar esperado, isso indica código com bug que está escrevendo mais que o esperado.
Com S3 Access Logging habilitado, você pode usar Athena para consultar logs e entender exatamente qual prefixo, IP ou usuário está gerando custos de API. Isso custa ~R$ 5,24/milhão de requisições em processamento Athena, mas economiza centenas de reais identificando operações redundantes.
Calculadora mental: como estimar seu custo operacional real em reais
Use essa fórmula para qualquer carga:
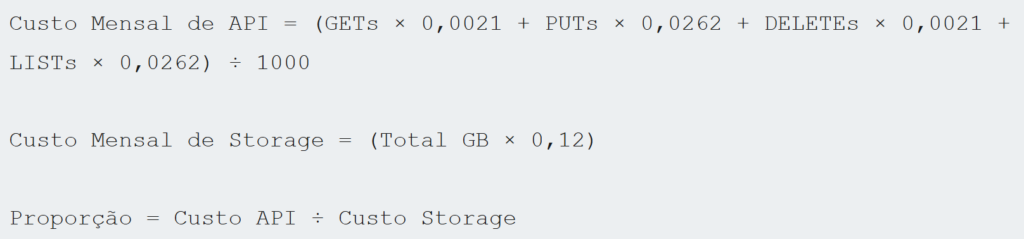
Se a proporção for maior que 10:1, você tem um problema de fragmentação e operações redundantes. Se estiver acima de 100:1, sua arquitetura de dados precisa de redesign urgente.
Na prática (em reais):
- 100M GETs/mês: R$ 210,00/mês em operações. Se seu storage é R$ 24,80/mês (200GB), proporção é 8,4:1, aceitável.
- 100M GETs + 10M PUTs/mês: R$ 210 + R$ 262,10 = R$ 472,10/mês em operações. Mesmos 200GB, proporção é 19:1, você precisa consolidar dados.
- 1B GETs/mês: R$ 2.100/mês em operações. Se storage é R$ 49,60/mês (400GB), proporção é 42:1, revisar pipeline de leitura imediatamente.
A maioria dos times descobre esses números apenas quando recebem a fatura. A diferença entre engenheiros que controlam custos e aqueles que não: eles calculam isso antes de colocar em produção.
Conclusão: a verdade que ninguém quer dizer
O S3 não é caro por armazenamento, é caro por operações. Você pode armazenar um petabyte por menos de R$ 123.520/mês. Mas acessá-lo ineficientemente pode custar dez vezes mais que isso em requisições de API.
A indústria é tímida em afirmar isso porque entra em conflito com a narrativa de “cloud é mais barato que on-premise”. É verdade se você arquitetar para isso. É mentira se você usar S3 como um disco rígido universal.
Se você está construindo algo com milhões de objetos pequenos, você não está resolvendo um problema de storage, está resolvendo um problema de design de dados. E nenhuma infraestrutura em nuvem resolve problemas fundamentais de design com desconto.
O custo real de S3 em reais não é pago em bytes armazenados, mas em decisões arquiteturais negligenciadas. Consolidar, cachear, particionar, essas não são “otimizações opcionais”. São obrigações econômicas que impactam diretamente seu bottom-line financeiro.



